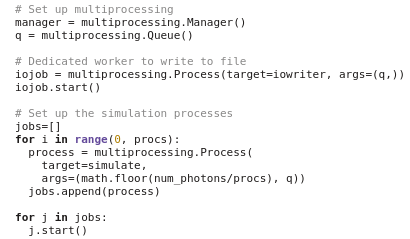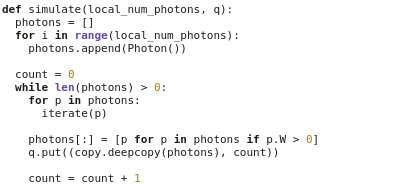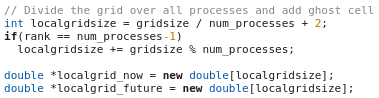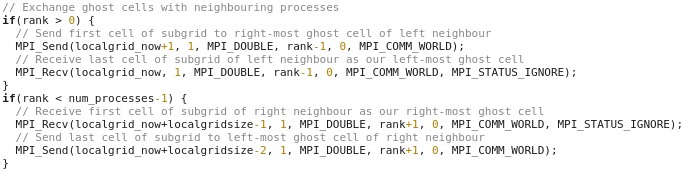In order to dramatically speed up your computations, you can create a program that uses multiple CPU cores in parallel instead of a single CPU core. Depending on the type of the problem, the speed-up could scale linearly with the number of cores. For example, on a quad-core machine, your program could run four times faster. When running on clusters with hundreds or thousands of CPUs, the benefits provided by parallel computing can be substantial. Various techniques are available to implement parallel computing, such as OpenMP, Python multiprocessing, or MPI.

Parallel computing
This webpage provides information and resources on parallel computing, offering professors insights into the benefits and techniques of utilizing parallel processing to enhance computational power and efficiency in academic research and teaching.
Parallel computing methods
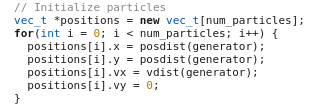
One of the easiest way to parallelize programs is with OpenMP. It is available for C, C++, and Fortran, and is present in most modern compilers.
To activate OpenMP on shared-memory systems (i.e., on a single computer), you only need to set a compiler flag. The addition of a single line near a for-loop will run it in parallel. The only limitation in this situation is the number of cores in the CPU.
The example below illustrates a simulation of falling and bouncing particles, parallelized at the physics.
The particle positions are initialized using the C++ random number generator. This is a serial part because the random number generator is not thread-safe.
Check the code: Intialize_particles.txt
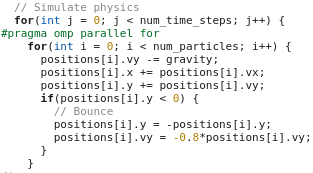
The actual physics is done by continuously updating the particle positions. By adding a #pragma statement above the for-loop, this part is run in paralle.
Compiling programs using OpenMP requires a compile flag. Its name will depend on the compiler, but is usually in the form of -fopenmp or -openmp. For example, to compile the above example use:
g++ main.cpp -fopenmp
See these tutorials for more information on how to program with OpenMP.
The example above was relatively straightforward, i.e. running a program in parallel because the particles were not interacting with each other.
Check the code: simulate_physics.txt
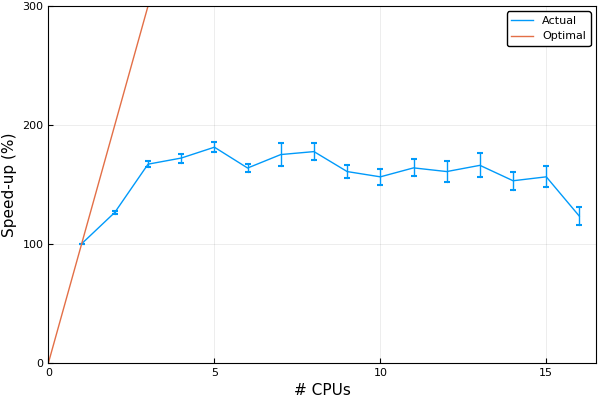
Interaction complicates things because multiple cores simultaneously access the positions of the particles, which can lead to undesired effects. There are also limitations in terms of how much speed-up can be obtained because there is always some overhead with parallel computing. For instance, the example above does not scale linearly with the number of threads. In fact, the program can become slower when adding more threads. Therefore, it is better to profile your program to see what the actual speed-up is, especially if you are considering RAC applications at Compute Canada.
A plot of the above example on an Intel Xeon E5520 processor reveals that while a speed-up of almost 2x can be obtained by using four threads, there is no gain when using more.
This plot was generated by timing the runtime of the program using different numbers of threads. This can be specified using the environment variable OMP_NUM_THREADS.